Retrieval-Augmented Generation (RAG)
How to build knowledge-grounded LLM applications: chunking strategies, embedding models, vector search, HyDE, hybrid retrieval, and the architecture decisions that determine pipeline reliability.
What Is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is an architecture that fetches relevant documents from an external knowledge store at query time and provides them to an LLM as context before it generates a response. Instead of relying solely on what the model learned during training, RAG gives the model access to up-to-date, specific, and verifiable information. The result is responses grounded in real documents rather than statistical patterns from training data.
Why RAG outperforms prompting for knowledge tasks
A language model's parametric knowledge — what it learned from training data — is static, unverifiable, and has a cutoff date. For any task that depends on private company data, recent events, or large document corpora, prompting alone fails because the model doesn't have the information. RAG solves this by converting the knowledge problem into a retrieval problem: index your documents, retrieve the relevant ones at query time, and give them to the model. The model's job becomes synthesis and reasoning over provided context rather than recall from weights.
Three properties make RAG preferable to fine-tuning for knowledge tasks: retrieved content is auditable (you can inspect exactly which documents informed a response), knowledge is updatable without retraining (add new documents to the index instantly), and retrieval failures are detectable (when no relevant document exists, you know it, rather than getting a confident hallucination).
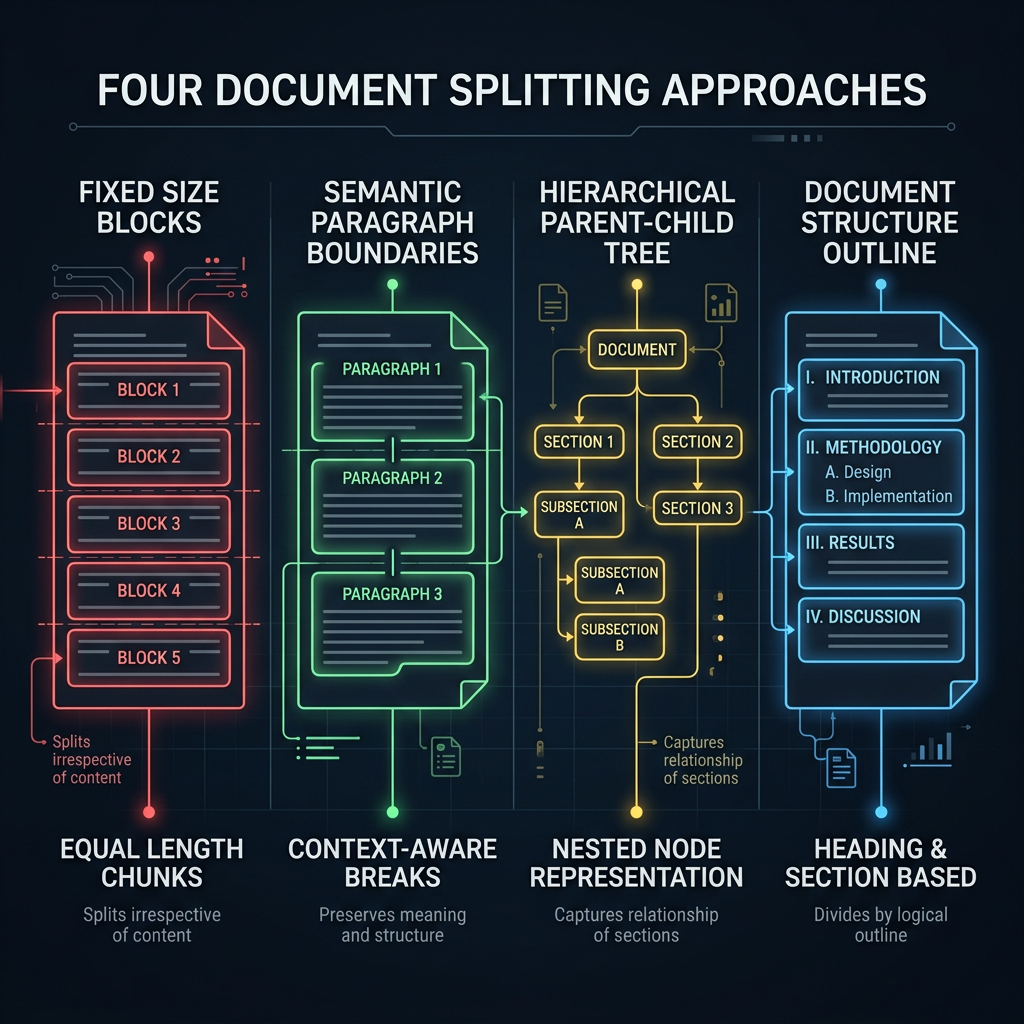
Chunking Strategies
Chunking is splitting source documents into pieces small enough to embed and retrieve meaningfully. The chunking strategy is one of the highest-leverage decisions in a RAG pipeline — poor chunking breaks retrieval even with a perfect embedding model and vector search configuration. Chunks that are too large dilute relevance signals. Chunks that are too small lose the context needed for coherent answers.
Common chunking approaches
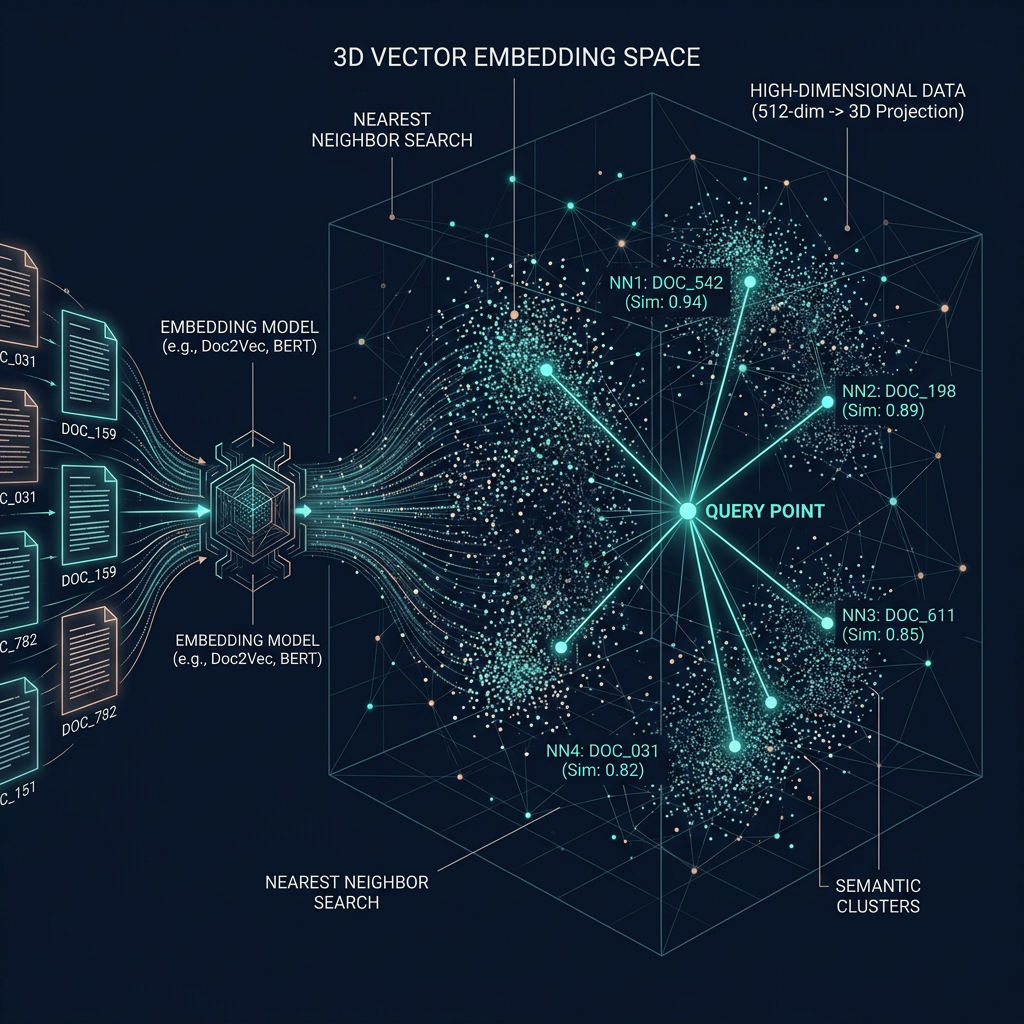
Embeddings and Vector Search
An embedding model converts text into a high-dimensional vector that encodes semantic meaning. Similar texts produce similar vectors. Vector search finds the k chunks whose vectors are closest to the query vector — typically measured by cosine similarity. The quality of your embedding model determines how well the system understands what "similar" means for your content domain.
Choosing an embedding model
General-purpose models (OpenAI text-embedding-3-large, Cohere Embed, Google Gemini embedding) work well for most English-language use cases. Domain-specific models outperform general ones on specialized vocabulary: legal, medical, code, or multilingual content. For on-premise or cost-sensitive deployments, bge-large-en-v1.5 and similar open-source models offer strong performance. Always evaluate on your actual data rather than benchmark leaderboards — distribution shifts between benchmarks and production corpora are common.
Vector store selection
For production, consider: pgvector (PostgreSQL extension, low operational overhead, good for existing Postgres deployments), Pinecone (fully managed, easy to start), Weaviate (strong metadata filtering), Qdrant (high-performance, open-source). For prototypes, Chroma or FAISS run locally with no infrastructure. The vector store matters less than chunking and embedding quality — optimize those first.
HyDE and Advanced Retrieval
Standard RAG embeds the user's query and searches for similar chunks. This fails when the query is short and semantically different from how the answer is expressed in documents. Advanced retrieval techniques address this mismatch between query style and document style.
Hypothetical Document Embeddings (HyDE)
HyDE generates a hypothetical answer to the user's question using the LLM, then embeds that hypothetical answer instead of the raw query. The hypothetical answer is written in the same style and vocabulary as real document content, so its embedding lands closer to relevant chunks in the vector space. This significantly improves recall for short or conversational queries against technical or formal document corpora. The cost is one additional LLM call per query before retrieval.
Multi-query retrieval
Generate 3–5 query variations from the original question, retrieve candidates for each, and deduplicate. This improves recall for ambiguous queries where a single formulation might miss relevant chunks that are reachable through slightly different phrasing.
Reranking
After vector retrieval returns top-k candidates (typically 20–50), a reranker model scores each chunk against the original query and returns the top-n most relevant (typically 3–8). Cross-encoder rerankers (Cohere Rerank, BGE Reranker) are slower than vector search but significantly more accurate. Always include a reranker in production pipelines with more than a few thousand chunks.
Hybrid Search
Hybrid search combines dense vector retrieval (semantic similarity) with sparse keyword retrieval (BM25 or full-text search). The two approaches have complementary failure modes: vector search excels at semantic similarity but misses exact keyword matches; keyword search excels at precise terms but fails on paraphrase and conceptual queries. Combining them with Reciprocal Rank Fusion (RRF) consistently outperforms either alone.
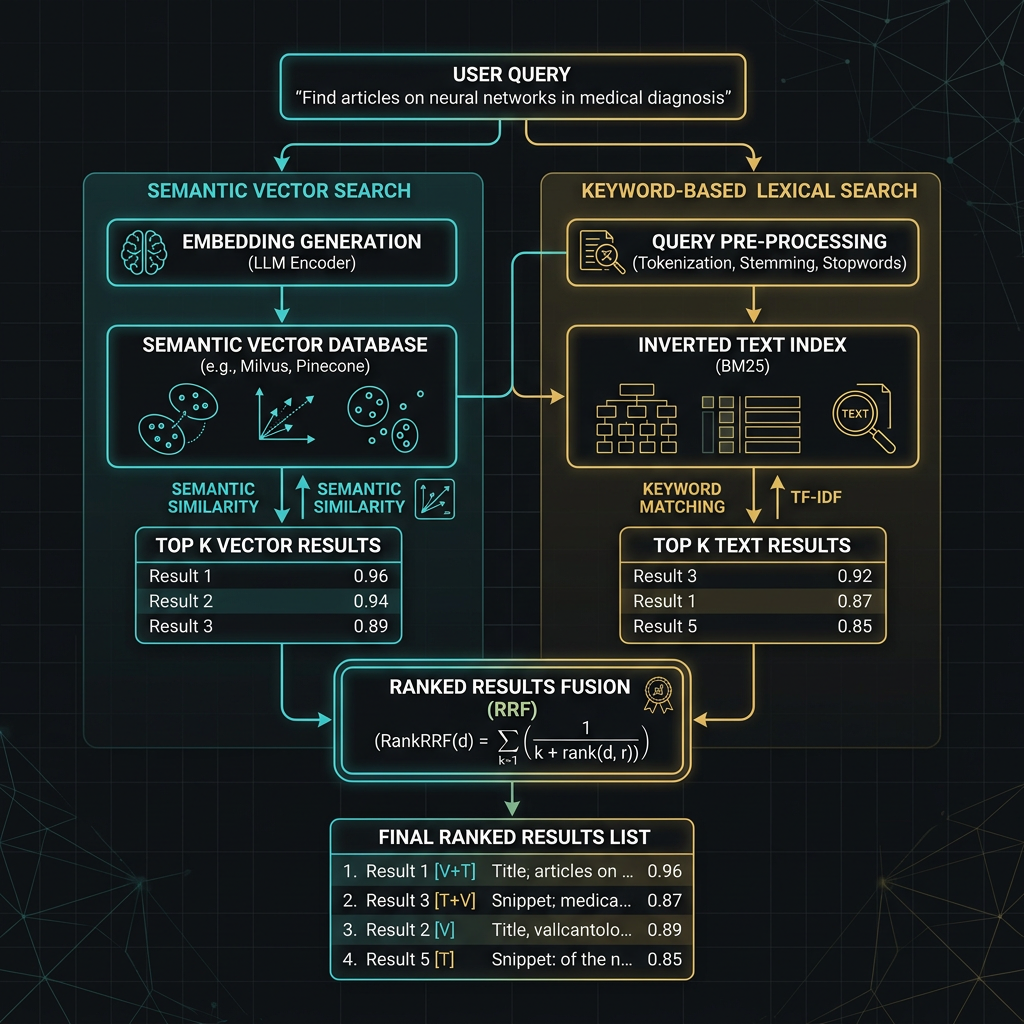
When to use hybrid search
Use hybrid search when your queries include both conceptual questions ("how does the refund process work") and exact-term lookups ("what is the SKU-2847 return policy"). Pure vector search handles the first well but may miss the second. Hybrid search consistently outperforms pure vector on corpora with mixed query types and is the standard approach in production enterprise deployments.
Production RAG Architecture
A production RAG system requires more than a vector store and an embedding call. Ingestion pipelines need to handle document updates without full reindexing. Retrieval needs fallbacks for low-confidence results. Generation needs citation tracking. Observability needs to trace which documents influenced each response so that failures can be debugged.
| Component | What to build | Why it matters |
|---|---|---|
| Ingestion pipeline | Incremental updates, document versioning | Full reindexing is slow; updates should be near-real-time |
| Query preprocessing | HyDE, multi-query, query rewriting | Raw queries often miss relevant chunks |
| Retrieval | Hybrid search + reranker | Best recall and precision at production scale |
| Context assembly | Deduplicate, rank, trim to fit context window | Too many chunks dilutes the LLM's focus |
| Citation tracking | Pass chunk metadata, instruct model to cite | Enables source verification and trust |
| Fallback handling | No-result responses, low-confidence flags | Prevents confident hallucination when retrieval fails |
| Evaluation | Retrieval recall, answer faithfulness, groundedness | Can't improve what you can't measure |