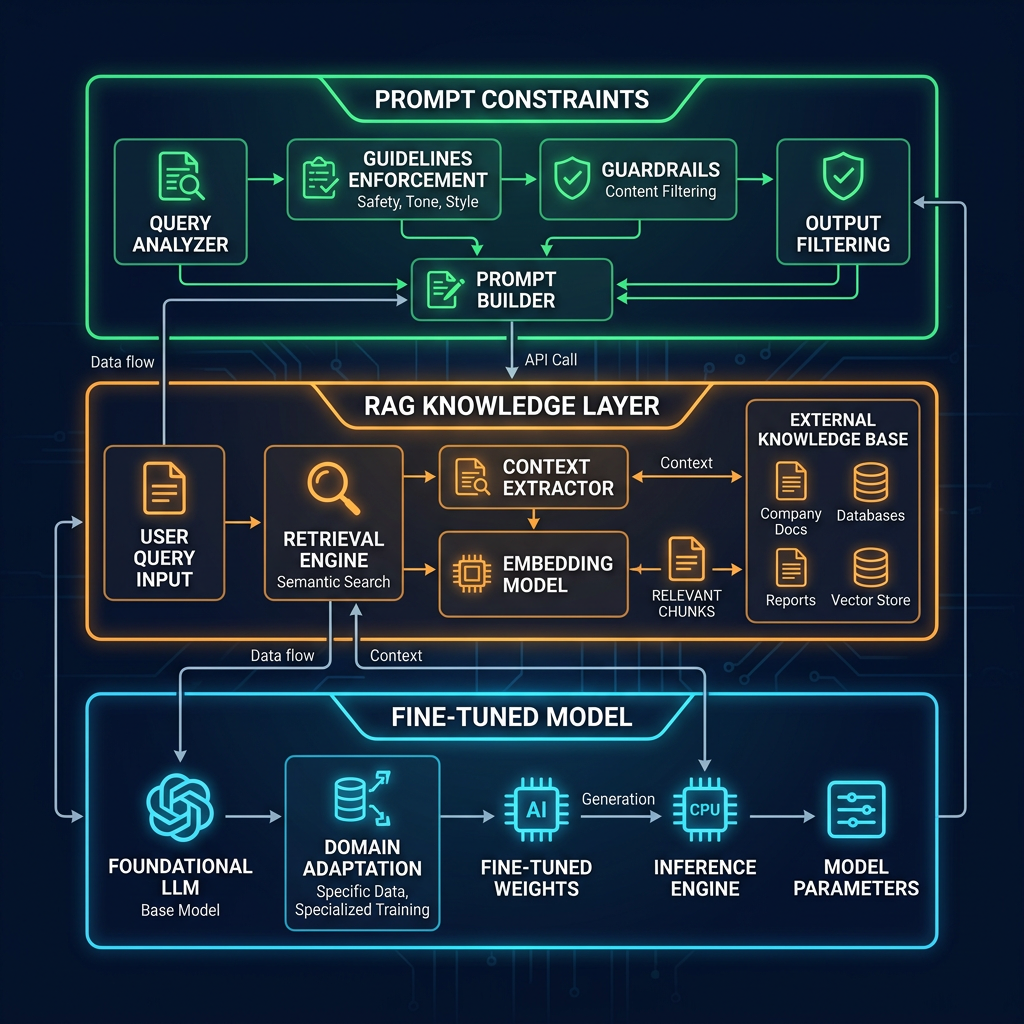
RAG vs Fine-Tuning vs Prompt Engineering
The three main approaches for improving LLM behavior each solve different problems. Here is a decision framework for picking the right one — and knowing when to combine them.
The Core Tradeoff
The three techniques solve different problems. Prompt engineering changes what you ask the model. RAG changes what the model knows at query time by retrieving relevant documents. Fine-tuning changes the model itself by updating its weights on task-specific data. Mixing up which problem you have leads to expensive solutions that don't fix the actual issue.
What problem are you actually solving?
Before choosing a technique, diagnose the failure mode. If the model understands the task but gives inconsistent outputs, that's a prompt engineering problem. If the model's outputs are consistently wrong because they depend on private, recent, or domain-specific knowledge the model wasn't trained on, that's a knowledge gap — and RAG is usually the answer. If the model consistently produces the wrong style, format, or reasoning pattern even with good prompts and relevant context, that's a behavioral gap that fine-tuning addresses. These three failure modes rarely overlap, and treating one with the tool for another wastes significant time and budget.
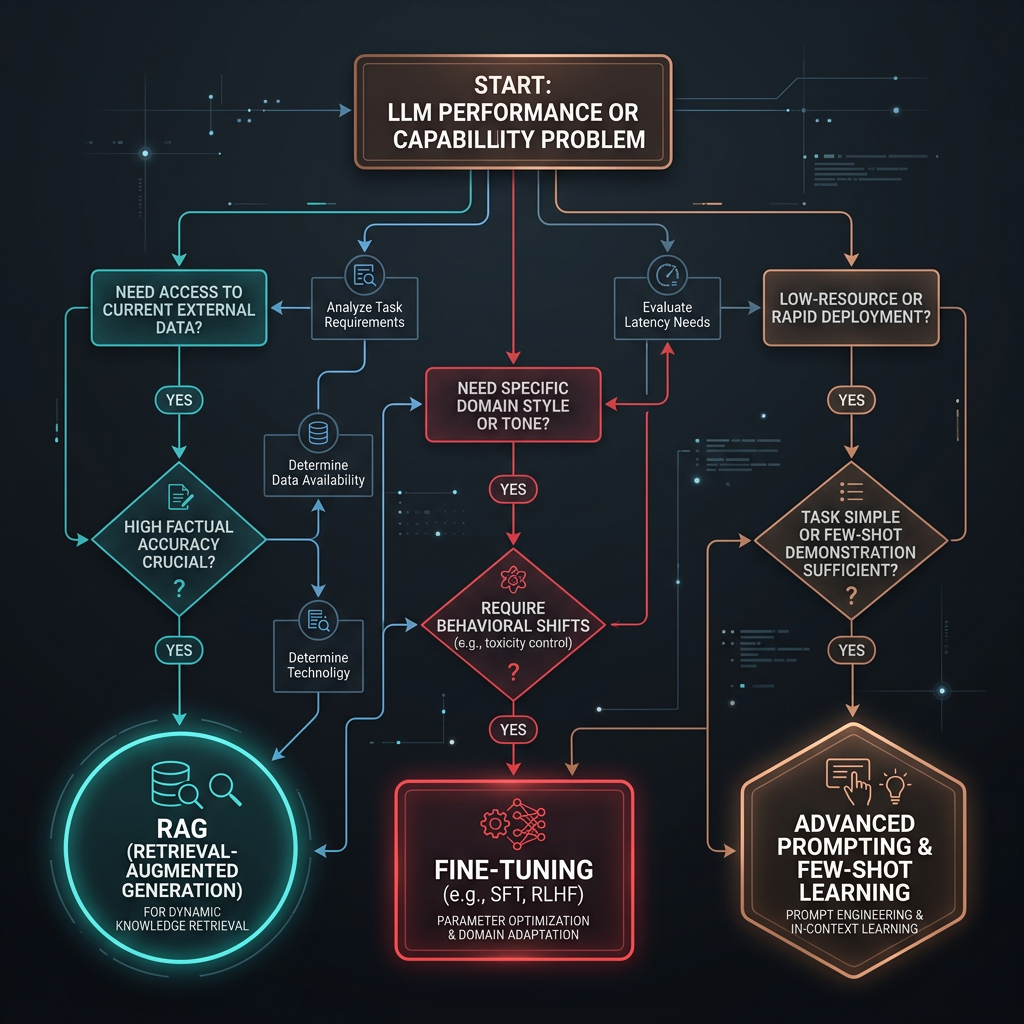
When Prompt Engineering Is Enough
Prompt engineering is the right first move in almost every situation. It's reversible, costs nothing to iterate, requires no infrastructure, and addresses the most common failure mode: the model has the knowledge and capability, but the instructions don't unlock it reliably. The mistake most teams make is abandoning prompting too early, before investing in few-shot examples, chain-of-thought, or structured system prompt design.
Where prompting alone works well
- Tasks within the model's training distribution: Summarization, classification, translation, code generation, writing assistance. The model has seen similar tasks; it just needs clear direction.
- Format and style enforcement: JSON output, specific tones, length constraints, structured reports. System prompt constraints handle these reliably.
- General reasoning tasks: Chain-of-thought handles multi-step logic, math, and inference without additional infrastructure.
- Low-volume or rapidly changing tasks: When the task definition changes often, prompts are faster to iterate than retraining.
The limits of prompting
Prompting fails when the model doesn't have the knowledge, not when it lacks the instructions. If your task requires current pricing, private company policies, proprietary research, or knowledge from after the model's training cutoff — adding more prompt instructions won't fix it. The model will confidently generate plausible-sounding but fabricated answers. This is the knowledge gap that RAG solves.
When RAG Is the Right Answer
Retrieval-Augmented Generation (RAG) fetches relevant documents at query time and adds them to the model's context before generating a response. It solves the knowledge gap problem without modifying the model. RAG is the preferred solution when the required knowledge is: too large to fit in a context window, changes frequently, is private or proprietary, or post-dates the model's training cutoff. In most enterprise AI deployments, RAG covers the knowledge access layer while prompting handles the behavioral layer.
RAG advantages over fine-tuning for knowledge tasks
- Updatable: Add new documents or change existing ones without retraining. The model sees the updated content immediately on the next query.
- Auditable: You can inspect exactly which documents influenced a response. Fine-tuned knowledge is baked into weights and can't be directly traced.
- Cheaper to iterate: Improving retrieval quality is faster and cheaper than a fine-tuning run. Chunking strategy, embedding model, and search parameters can all be tuned independently.
- Reduces hallucination on grounded tasks: When the model has the right document in context, it's much less likely to fabricate. Prompt instructions to "only answer from provided context" further constrain this.
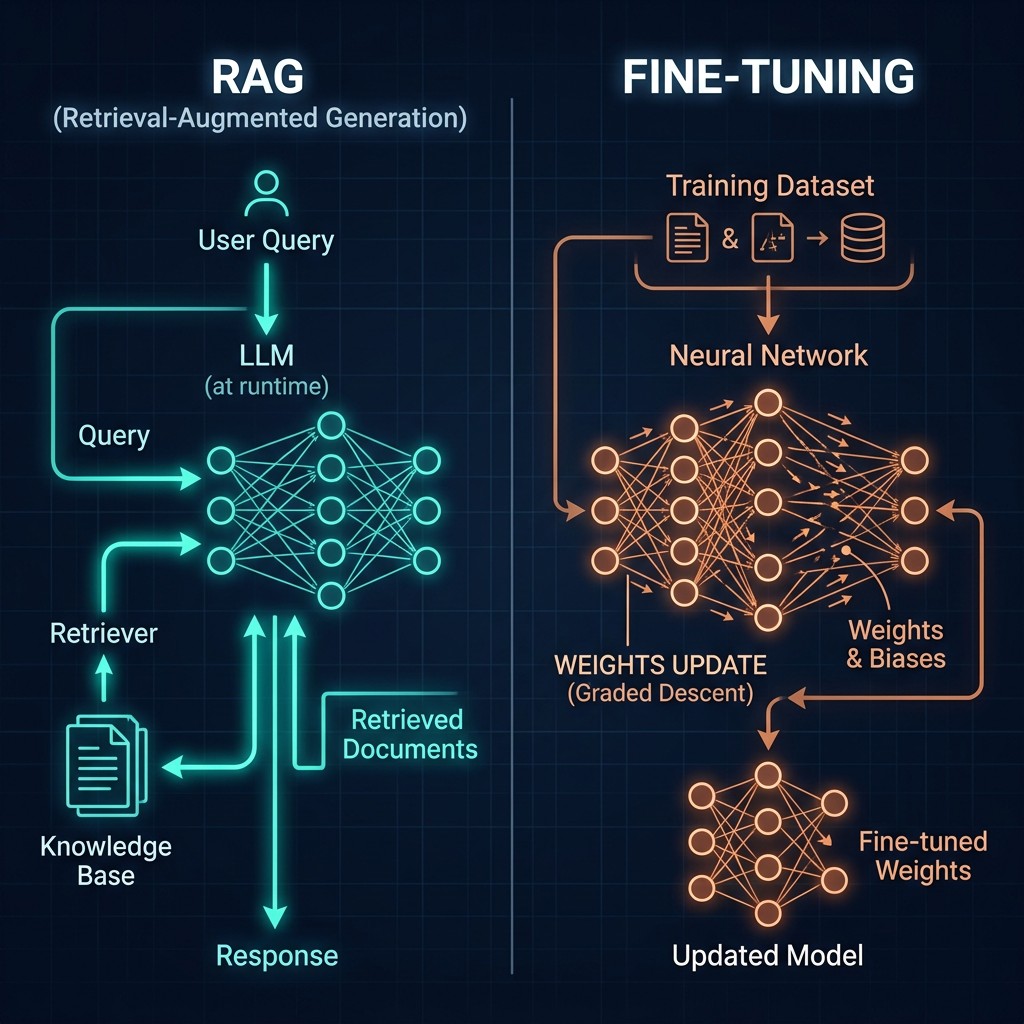
When RAG is not the answer
RAG doesn't help when the problem is behavioral, not informational. If the model consistently produces the wrong output format, uses the wrong reasoning pattern, or misunderstands the task type — retrieval won't fix it. RAG also has higher latency than prompting alone (retrieval adds a round trip), adds infrastructure complexity, and can introduce retrieval errors that contaminate responses. Don't reach for RAG to solve a prompting problem.
When Fine-Tuning Makes Sense
Fine-tuning updates a model's weights on a curated dataset to change its default behavior. It's appropriate when: you have a high-volume, narrow task where the behavioral gap can't be closed with prompting; you need a smaller, cheaper model to match the quality of a larger one on a specific task; or you need to reliably enforce output formats and styles at a level that system prompts alone don't achieve. Fine-tuning is a significant investment — data curation, training, evaluation, and ongoing maintenance — and is rarely the right first step.
The fine-tuning checklist
Before committing to a fine-tuning project, confirm all three: (1) You've tried thorough prompt engineering including chain-of-thought and few-shot examples. (2) You have at least 500–1,000 high-quality labeled examples, with a clear labeling rubric. (3) The task is stable — if requirements change frequently, you'll spend more time retraining than shipping. If any of these isn't true, solve the prerequisite first.
Full Comparison Matrix
| Dimension | Prompt Engineering | RAG | Fine-Tuning |
|---|---|---|---|
| Setup time | Hours | Days–weeks | Weeks–months |
| Cost to iterate | Near zero | Low–moderate | High (per run) |
| Latency impact | Minimal | +retrieval latency | None (same inference) |
| Knowledge freshness | Training cutoff | Real-time | Training cutoff |
| Auditability | Full (read the prompt) | High (inspect retrieved docs) | Low (baked into weights) |
| Solves: knowledge gaps | No | Yes | Partially (unreliably) |
| Solves: style/format gaps | Partially | No | Yes |
| Solves: task instruction gaps | Yes | No | Partially |
| Best first step | Always start here | After prompting | Last resort after both |
Hybrid Approaches
Production systems often combine techniques. The most common pattern: a fine-tuned base model (for style and format consistency) that uses RAG for knowledge access, wrapped in a carefully designed system prompt. Each layer solves a different problem. The mistake is using all three to compensate for weakness in one — a system with bad prompting, unreliable retrieval, and undertrained fine-tuning is the worst of all worlds.