What Are Multi-Agent AI Systems?
A multi-agent AI system is an architecture in which two or more AI models (agents) collaborate to complete a task—each agent perceiving input, reasoning, and taking actions within its scope, while communicating results to peers or a coordinating orchestrator. Unlike a single LLM call, multi-agent systems can parallelize work, apply specialist models to sub-problems, and maintain context across long-running tasks that exceed a single context window. The defining feature is that individual agents operate autonomously within defined boundaries rather than waiting for human instruction at each step.
The case for multiple agents emerges from three constraints of any single model call:
Context limits
Even 200k-token models cannot hold an entire codebase, research corpus, or long-running session in working memory. Agents can divide work across independent contexts.
Specialization
A model prompted as a "security auditor" consistently outperforms the same model answering general questions. Dedicated agents with focused system prompts perform better on their domain.
Parallelism
Independent subtasks—researching three competitors, writing four page sections—can run concurrently. Sequential single-model pipelines leave most of that time on the table.
The tradeoff is coordination overhead, error propagation, and observability complexity. Multi-agent systems are not always the right tool—start with a single model and add agents only when a concrete bottleneck justifies it.
Coordination Patterns
How agents communicate and delegate work determines everything about a system's reliability and scalability. Three patterns cover the majority of production use cases.
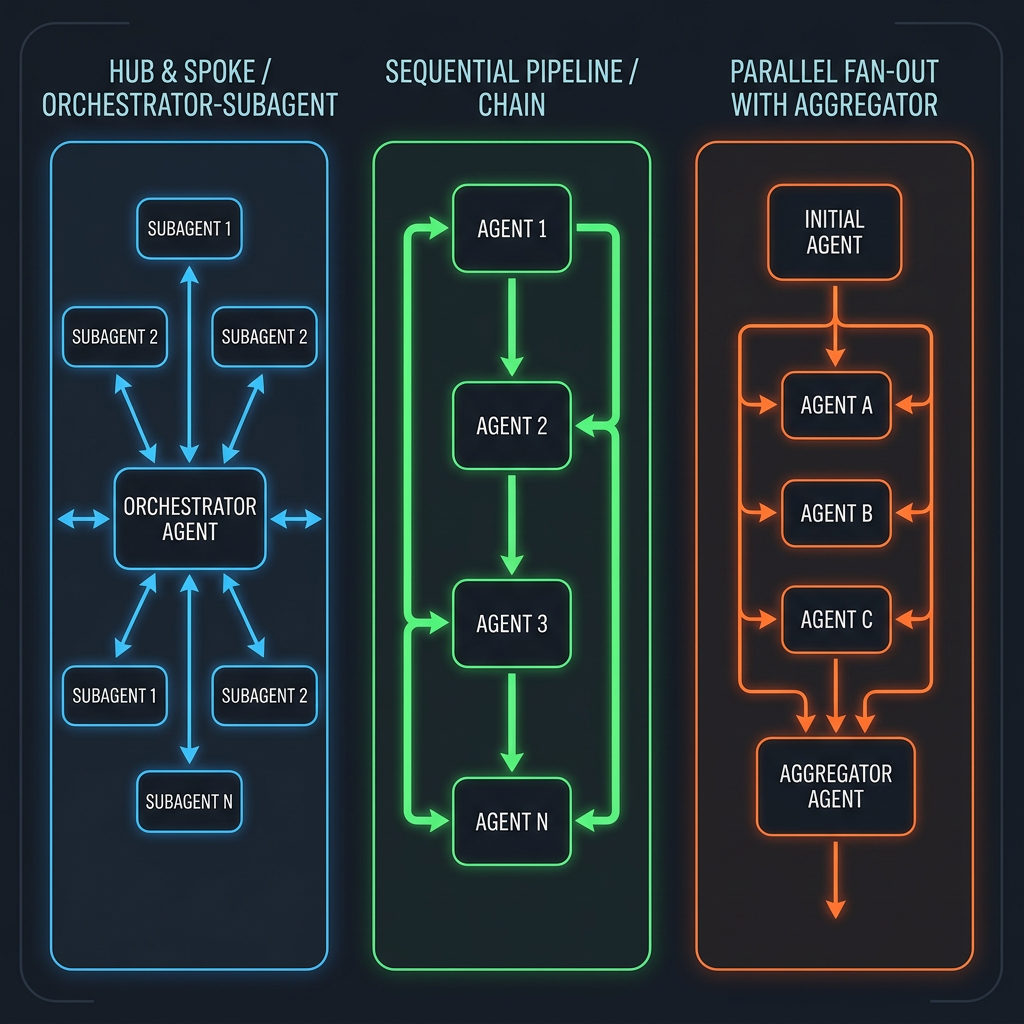
Orchestrator-Subagent
A central orchestrator receives the top-level goal, decomposes it into subtasks, dispatches each subtask to a specialized subagent, and synthesizes the results. The orchestrator never executes domain tasks directly—it only plans and coordinates. Subagents are stateless from the orchestrator's perspective: they receive a task, complete it, and return output.
This is the most common pattern for complex reasoning tasks. The orchestrator can be a powerful frontier model (e.g., Claude Opus) while subagents use cheaper, faster models for execution. The key design choice is what the orchestrator retains in its context versus what lives in shared storage.
Sequential Pipeline
Each agent in a chain processes output from the previous agent before passing results to the next. A content pipeline might run: researcher → writer → editor → publisher. Sequential pipelines are simple to debug because the data flow is linear, but they have no concurrency—the end-to-end latency equals the sum of every agent's latency.
Use sequential pipelines when each stage must validate and possibly reject the previous stage's output, or when the output of stage N directly forms the entire input to stage N+1.
Parallel Fan-Out
An orchestrator dispatches multiple independent subtasks simultaneously, waits for all to complete, then aggregates results. A competitive analysis system might simultaneously research five competitors in parallel rather than sequentially. Fan-out reduces total wall-clock time proportionally to the number of parallel branches, but requires the orchestrator to handle partial failures gracefully—one slow or failed agent should not block the entire result.
Agent Memory Architecture
Memory is what separates a stateless function call from an agent that can learn and improve across a session. Four memory layers, from fastest to most persistent:
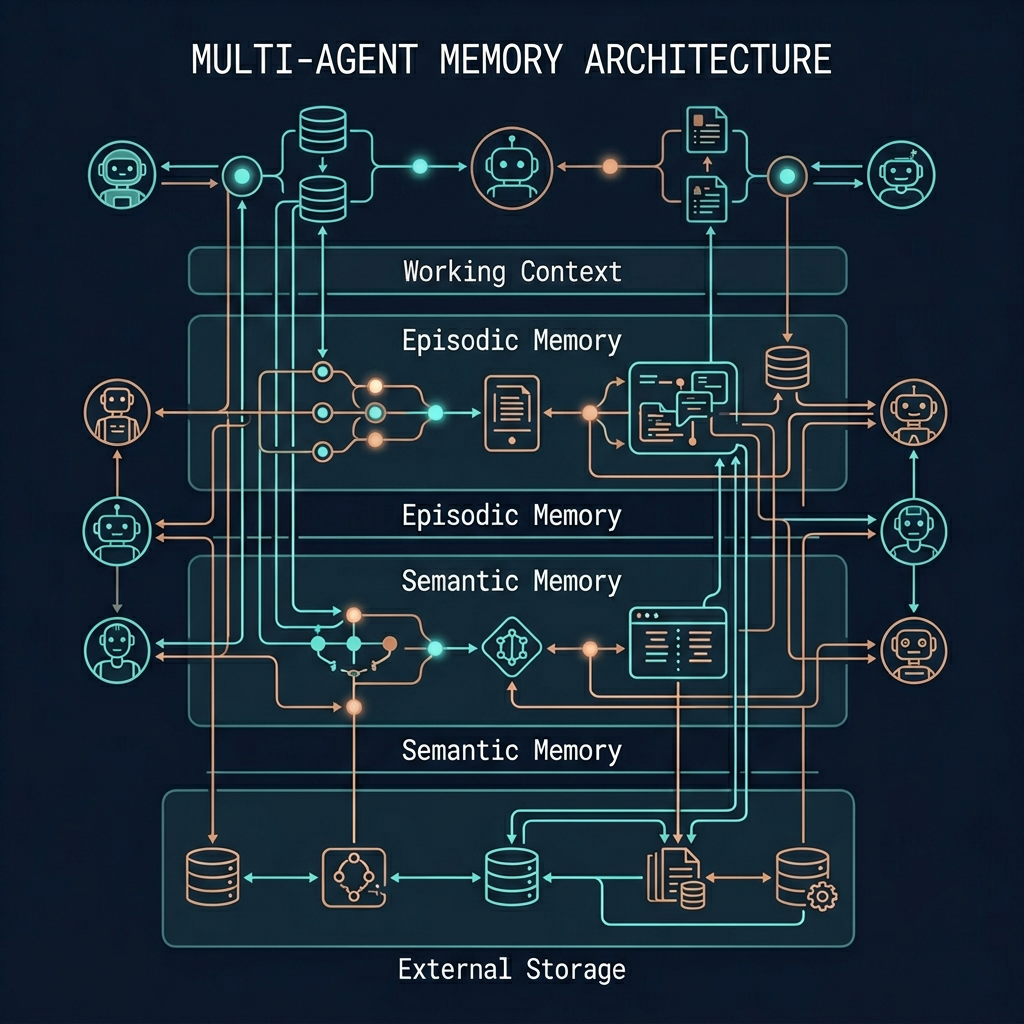
In-Context Memory
Everything in the current context window—conversation history, tool call results, intermediate reasoning. Fast to access, limited in size, lost when the session ends. Think of it as working memory.
Episodic Memory
Summaries and key events from past sessions, stored externally and retrieved at the start of new sessions. Enables an agent to "remember" previous interactions without replaying the full history.
Semantic Memory
Facts, domain knowledge, and learnings stored as embeddings in a vector database. Retrieved via semantic similarity search at query time—similar to RAG but for agent state rather than external documents.
External Storage
Structured databases, file systems, APIs—anything the agent can read and write via tools. The most durable layer. Multiple agents can share a database to coordinate work asynchronously.
Which Memory Layer to Use?
A practical guideline: keep the current task state in-context, distill important decisions into episodic summaries, store reusable knowledge in semantic memory, and write final outputs to external storage. Most agent failures come from trying to keep too much in context and hitting token limits mid-task.
Tool Use and the MCP Standard
Agents extend their capabilities through tools—functions the model can invoke to interact with the world. Tools are the bridge between language and action: searching the web, running code, querying databases, calling APIs, and writing to storage all happen through tool interfaces.
Model Context Protocol (MCP) is Anthropic's open standard for agent-to-tool communication. A growing ecosystem of MCP servers expose tools from GitHub, Slack, databases, browsers, and more—letting agents connect to existing infrastructure without custom integration code. If you're building tools for agents, implementing MCP compatibility opens access to a standardized client ecosystem.
Designing Reliable Tool Interfaces
Tool quality directly determines agent reliability. A poorly described tool generates hallucinated parameters. An over-broad tool creates unpredictable side effects. Guidelines for production tool design:
| Principle | Why It Matters | Example |
|---|---|---|
| One clear action per tool | Models invoke tools more reliably when each has a single, unambiguous purpose | search_web not research_and_summarize |
| Explicit parameter descriptions | The model constructs parameters from the description—ambiguous docs produce wrong calls | "ISO 8601 date string, e.g. 2025-01-15" not "a date" |
| Idempotent writes where possible | Agents retry on errors; a non-idempotent write tool causes duplicates | Upsert by ID rather than always-insert |
| Structured error returns | The model must distinguish "not found" from "permission denied" from "network error" | {"error": "not_found", "id": "abc"} not a raw exception |
| Limit blast radius | Tools that can delete or overwrite should require explicit confirmation parameters | delete_file(path, confirm=True) |
Tool Calling Patterns
Most frontier models support parallel tool calling—invoking multiple tools simultaneously in a single response turn. Use parallel calls for independent lookups (search three sources at once) but sequential calls when the output of one tool informs the next tool's parameters. The agent loop typically runs: observe → reason → act → observe until the task is complete or a stopping condition is reached.
When to Use Multi-Agent Systems
The operational overhead of multi-agent coordination—prompt engineering for each agent, managing inter-agent communication, observability across N model calls—is substantial. Reach for agents when you hit a concrete wall with simpler approaches.
Good fit for multi-agent
Tasks that are too long for one context window, tasks with clearly separable subtasks, tasks requiring different models or personas at different stages, tasks where parallelism directly reduces user-facing latency.
Poor fit for multi-agent
Simple Q&A or single-step generation, tasks where errors compound across agents unpredictably, latency-sensitive applications where coordination overhead matters, early-stage features where requirements are still changing.
The Cost of Coordination
Every agent-to-agent message is a model call. A 4-agent pipeline where each agent uses 5k tokens costs 4x the tokens of a single call—before adding the orchestrator's own reasoning. Token cost and latency scale with agent count. Always benchmark a well-prompted single-model solution before adding agents; the baseline is often more capable than expected when given the right context and tools.
Building Reliable Multi-Agent Systems
Multi-agent systems fail in ways that single-model calls do not: cascading errors, context divergence between agents, hallucinated tool calls, and agents that loop indefinitely. Building for reliability requires intentional design at every layer.
Structuring Agent Handoffs
The interface between agents is the highest-failure point. Use structured output formats (JSON with explicit schema) for inter-agent communication rather than free prose. An agent that receives "the analysis is done" from a peer has no actionable data. An agent that receives {"status": "complete", "findings": [...], "confidence": 0.87} can reason precisely about what to do next.
- Define output contracts before building agents Each agent's output schema is a contract. Write it first, then implement the agent to match it. This prevents output drift that silently breaks downstream agents.
- Validate all inter-agent outputs with schemas Use Pydantic, Zod, or JSON Schema to validate every agent output before passing to the next. Fail loudly on contract violations—silent garbage propagates and is hard to debug.
- Set explicit stopping conditions Every agent needs a maximum iteration count and a clear success/failure definition. Agents without stopping conditions loop indefinitely when stuck, burning tokens and blocking downstream work.
- Handle partial failures gracefully In fan-out patterns, a single failed subagent should not fail the entire pipeline. The orchestrator should collect results from successful agents and either retry the failure, skip it, or degrade gracefully based on criticality.
- Implement observability from day one Log every agent invocation with input, output, token count, and latency. Multi-agent debugging without traces is guesswork. Tools like LangSmith, Braintrust, and custom OpenTelemetry setups all work—but you need something before production.
The Trust Hierarchy
In a multi-agent system, agents receive instructions from other agents—not just humans. This creates a trust hierarchy that must be explicitly designed. An orchestrator agent should have different permissions than a subagent. A subagent receiving instructions via a message queue should not automatically have write access to production storage just because another agent told it to write there. Design permission boundaries as if agents were separate microservices with their own access controls.
Prompt injection risk: If a subagent reads from external sources (websites, emails, documents), malicious content in those sources could contain instructions designed to hijack the agent's behavior. Treat all externally-sourced text as untrusted input and sanitize it before including it in agent prompts—especially in orchestrators that route instructions to other agents.
Production Architecture Considerations
Moving a multi-agent prototype to production surfaces infrastructure requirements that don't exist in single-model systems.
| Concern | Challenge | Approach |
|---|---|---|
| State management | Agent sessions can run for minutes to hours; in-memory state is lost on crash | Persist task state and intermediate results to a database after each agent step |
| Idempotency | Network failures cause retries; agents must not double-process or double-write | Assign unique IDs to each task; check completion before executing |
| Rate limiting | Fan-out sends bursts of parallel API calls that can exceed provider limits | Implement a rate limiter and exponential backoff at the orchestrator level |
| Cost control | Agents can loop and burn tokens; a single stuck agent can run up unexpected bills | Set per-task token budgets and kill switches in the orchestrator |
| Observability | Debugging a 10-agent pipeline from logs alone is impractical | Use distributed tracing with parent-child spans per agent invocation |
| Human escalation | Agents encounter ambiguous situations they cannot resolve autonomously | Build explicit "escalate to human" actions and checkpoints at high-risk steps |
Starting Small
Production-grade multi-agent infrastructure is complex to operate. A pragmatic path: start with a single well-instrumented agent loop, add a second agent only when the first proves insufficient, and extract shared infrastructure (observability, state storage, rate limiting) into reusable components as the system grows. Systems built incrementally are far easier to debug than full architectures built speculatively.